Machnie Learning¶
In most scientific experiments, we get an observation for each input through an unknown system as shown in Fig. 1. Our goal is to discover an input to generate the desired observation, and it can be systemically achieved if we know the unknown system. However, the unknown system is a black-box system in most cases because it is incomprehensibly complex.
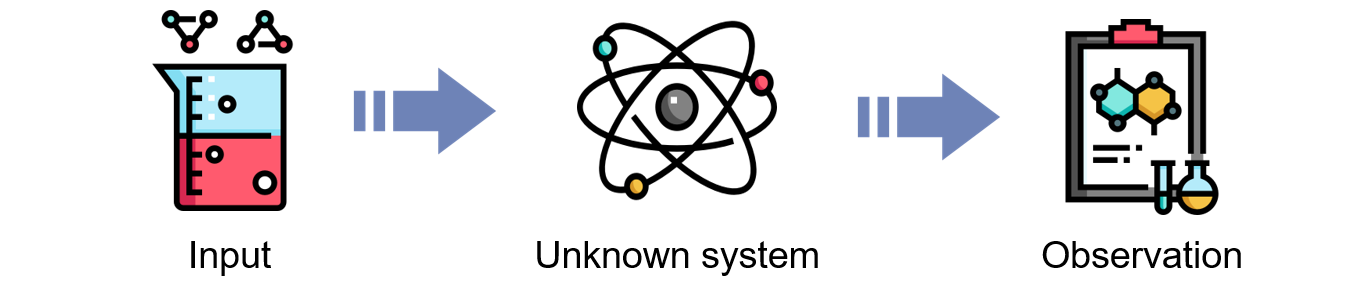
Figure 1. Scientific experiments.¶
Although we cannot understand the complex nature, we can collect data containing input and output pairs from the unknown systems by measuring the output for each input. This collected data with the input and output pairs are called dataset in machine learning.
For a given dataset, machine learning conversely approximates the unknown system that generated the outputs from the inputs. Therefore, by exploiting machine learning, we can predict the outputs of the unknown systems for the given inputs without time-consuming computer simulations and actual experiments.
ChemAI provides a code-free machine learning for your datasets formatted by chemical formula, SMILES, crystal structure, and numeric vector. The overall process to train the machine learning models is introduced in the following video guide.
- Training Results
Model Training¶
Machine learning model is a trainable function to approximate the target systems. As shown in Fig. 2, the goal of the training is to generate a machine learning model that accurately approximates the unknown systems described by the input and output pairs in the given datasets.
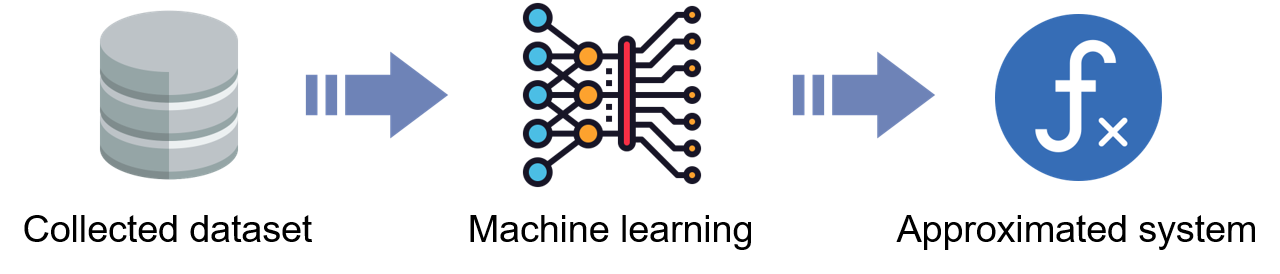
Figure 2. The goal of machine learning.¶
1. Training Dataset Upload (Step 1)¶
First of all, you should upload your dataset containing the input and output pairs to train the machine learning models. ChemAI is designed specifically for chemical data and supports four types of input formats: chemical formula, SMILES, crystal structure, and numeric vector. The user dataset should be organized according to the following guideline for each input format.
1.1. Dataset Formats¶
1.1.1. Chemical Formula¶
A user dataset should be organized as shown in Table 1 to train the machine learning models to predict a target property from a given chemical formula.
The user datasets should be uploaded by .xlsx file for the format of the chemical formula.
You can download an example Excel file for the chemical formula dataset: example_chemical_formula.
Chemical Formula |
Target Property |
|---|---|
ZnO |
3.26 |
ZrO2 |
4.99 |
Pb0.85Ge0.15Te |
0.36 |
1.1.2. SMILES¶
In the machine learning of ChemAI, SMILES representation can be used to build a machine learning model that predicts target properties from molecular structures.
The user datasets can be uploaded by .xlsx file, and the dataset should be organized as shown in Table 2.
You can download an example Excel file for the SMILES dataset: example_smiles
SMILES |
Target Property |
|---|---|
Oc1ncnc2scc(c3ccsc3)c12 |
2.25 |
O=C1CCCCCN1 |
-0.08 |
Nc1ccc(cc1)c2nc3ccc(O)cc3s2 |
3.2 |
1.1.3. Crystal Structure¶
Unlike the chemical formula and SMILES formats, the user dataset of crystal structures should be uploaded by .zip file containing metadata.xlsx and .cif files.
Note
The metadata file in the crystal structure dataset must be saved metadata.xlsx.
In the metadata file, the name of the CIF files and the target property should be provided for each row as shown in Table 3.
You can download an example ZIP file for the crystal structure dataset: example_crystal_structure
CIF File Name |
Target Property |
|---|---|
mp-1143 |
5.854 |
mp-4842 |
2.494 |
mp-7907 |
2.142 |
1.1.4. Numeric Vector¶
ChemAI also provides machine learning for generic datasets of numeric vectors.
For this machine learning, the user dataset can be uploaded by .xlsx file organized as shown in Table 4.
You can download an example Excel file for the SMILES dataset: example_numeric_vector
Feature1 |
Feature2 |
Feature3 |
Target Property |
|---|---|---|---|
34 |
236 |
7 |
3.35 |
45 |
435 |
9 |
4.32 |
1.2. Problem Definition¶
After uploading the training dataset, the prediction problem can be defined in the feature table of ChemAI. In the feature table, you can define the input features of the machine learning models by enabling the checkbox. Also, you can define the output of the machine learning models by enabling the radio button.
2. Model Configuration (Step 2)¶
2.1. Model Selection¶
After uploading the training dataset and defining the prediction problem are completed, you can select machine learning models for the input formats of chemical formula and numeric vector. Of course, there is a trade-off between training efficiency and prediction accuracy. If you need a quick result of machine learning, you can select interpretable or efficient algorithms by placing the rangebar to the left.
- Interpretable Algorithms
- Accurate Algorithms
For SMILES and crystal structure datasets, the following state-of-the-art deep learning algorithms are automatically selected.
- Graph Neural Networks for General Graphs
- Graph Neural Networks for Crystal Graphs
2.2. Hyperparameter setting¶
Most machine learning algorithms require appropriate hyperparameters. However, hyperparameter tuning can be cumbersome for the users. To support the hyperparameter setting, ChemAI provides a five step hyperparameter search. These steps are categorized according to efficiency and exploration, and you can set the search level using the rangebar.
Warning
In the best version of ChemAI, the hyperparameter setting option is not available.
3. Training Options (Step 3)¶
If the settings for machine learning algorithms and hyperparameters have been completed, the next step is to configure training options.
3.1. Training configuration¶
ChemAI automatically selects the best training parameters according to the prediction performances on validation datasets. You can select the ranges of candidate training parameters that will be evaluated in the training of machine learning algorithms.
Warning
In the best version of ChemAI, the training configuration option is not available.
3.2. Outlier Removal¶
Outlier indicates an abnormal data, and it sometimes disturbs the training of machine learning algorithms. For the accurate training of the algorithms, ChemAI provides an automated outlier removal. If the outlier removal option is enabled, the outlier data in the uploaded user dataset will be removed according to data distributions.
3.3. Transfer learning¶
Transfer learning is a useful function when the number of data in user dataset is insufficient. If this option is enabled, machine learning models pre-trained on Materials Project, NOMAD, and other public databases will be used to solve your prediction problems.
Warning
In the best version of ChemAI, this transfer learning is not available.
4. Training Job (Step 4)¶
Once both the prediction problem definition and algorithm setting are complete, you can start the model training task by clicking the ‘Train machine learning model’ button.
When the ‘Training machine learning model’ button is clicked, it switches to the progress screen showing the status and results of the machine learning jobs. At the top of the Training Jobs, you can check the status of the machine learning job in progress, and from the second row, the final status of the already completed job is displayed. The information on the dataset used for the training job and the start time of the job is also displayed. By clicking the job name of a normally terminated job, you can check the model training results. For a more detailed explanation of this, please refer to the next ‘Training Results’ section. If the job is terminated abnormally, an error status is displayed. By clicking on the part written as an error, you can know the reason for the error.
Training Results¶
1. Evaluation Results¶
For a model training job that has been normally finished, ChemAI displays evaluation results for each algorithm used for prediction. As prediction performance, MAE, RMSE, and R2 score values for each algorithm are displayed.
If you want to see more detailed evaluation results, click the machine learning algorithm name in the Prediction Model column. When the arbitrary prediction model is selected, ChemAI shows the prediction results, target distribution, and error distribution information of that model.
1.1. Prediction results¶
Prediction results present the most intuitive result to the user. The result of a scatter plot of the predicted values for the target values given in the dataset is presented.
1.2. Target distribution¶
Target distribution shows the number of data for each target range. This is useful for looking at the overall distribution of target values used for prediction.
1.3. Error distribution¶
Error distribution displays the mean values of errors for each target range. This analysis chart helps you to compare and analyze the predictive performances by target range.
2. Actions¶
If you have completed the prediction performance comparison and analysis for each prediction algorithm, the model determined to be the optimal predictive model can be separately managed through the Actions function.
2.1. Download model¶
When you click the Download model button, the model file is immediately downloaded to your local computer. You can use the predictive model file by writing a Python script personally.
2.2. Download interpretation¶
In addition to prediction model files, ChemAI provides interpretation results derived from the training process of interpretable models such as Decision Tree Regression or Symbolic Regression. For the decision tree algorithm, all interpretation results for each branch are displayed through the provided figure file. You can use this to try to interpret the results in more detail.
For the symbolic regression, Download interpretation in Actions provides branch information containing simple arithmetic formulas for specific features.
2.3. Store model¶
If you want to store your own prediction model within ChemAI or share it with other users, you can use the Store model function. Your prediction model can be stored in repository storage in the server through the Store model function in Actions. The Store model proceeds through two writing stages for metadata and visibility of the application.
Note
Metadata of Application
ChemAI requires minimal metadata about the predictive model that the user wants to store. The minimum input fields for metadata of application are title, category, input type, target property, and unit.
Note
Visibility of Application
When the process of entering metadata of the application has been completed, the selection step for visibility must be carried out. Visibility of Application consists of three options: All in a private repository, All in the public repository, and Runnable in the public repository.
All in private repository (Option 1) - Your application will be stored in a private repository of your account. If the application is stored privately, no one can access this application.
All in public repository (Option 2) - All information about your application will be publicly opened in the public repository of the platform. All users of the platform can publicly use your application in developing other applications. It will be very helpful for users who want to employ your trained model in their applications.
Runnable in public repository (Option 3) - Your application with only a runnable model will be stored in the public repository of the platform. All users of the platform can access all information about your model except for the model file. The users can predict their data using your application, but they cannot develop a new application using your prediction model.
When the selection for visibility is completed, finally, all the procedures for the Store model function are completed by clicking the ‘Store this application’ button.
3. Training configurations¶
The prediction performance can be fully understood and accepted only when the prediction results are presented along with information on which target property was predicted with how much accuracy. Thus, in addition to the comparative evaluation and store function of prediction model, ChemAI also provides the information of training configurations used for model training. The Training configurations display setting information for the Imputation method, Data configuration, Model Configuration, and Training Options.